FAQ
If my aesthetic preferences have changed, do I need to make a new account to get an up to date ranking?
Nope! Just keep rating more, the aesthetics' ratings will change again, and move up or down in the ranking correspondingly.
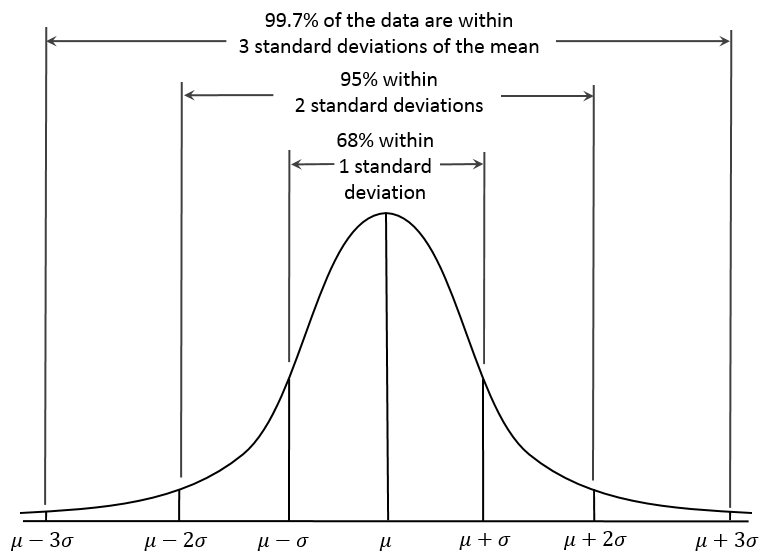
Each aesthetic has two values associated with it:
- its rating (μ): how much you (dis)like an aesthetic (what your "true" rating of it most likely is)
- its uncertainty (σ): how sure the algorithm is about the rating value (the width of the region around the rating value where your "true" rating most likely is: the rating ± the uncertainty)
(image source:
Dan Kernler)
If you often prefer a certain aesthetic over others, its rating will increase more and more, but less and less each time since the algorithm becomes quite certain that you actually like it (the uncertainty value decreases).
Now, if you start to dislike it and chose others over it, then the uncertainty value will increase again, and its rating will decrease (faster the more often you do it, and the higher the uncertainty gets), until it becomes more certain again that its rating is at the right value.
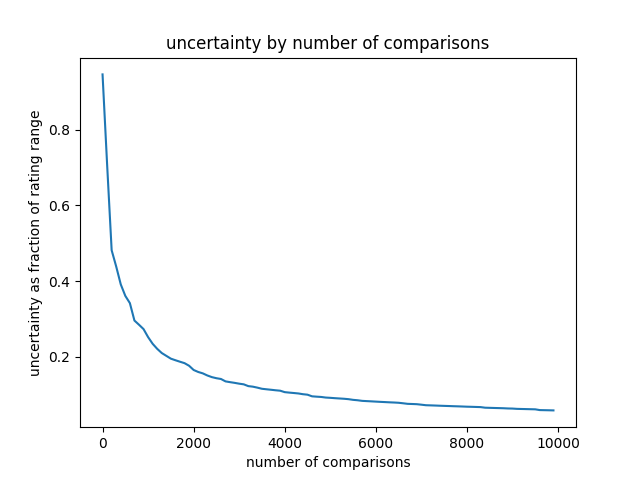
How many comparisons do I need to do before ratings become accurate?
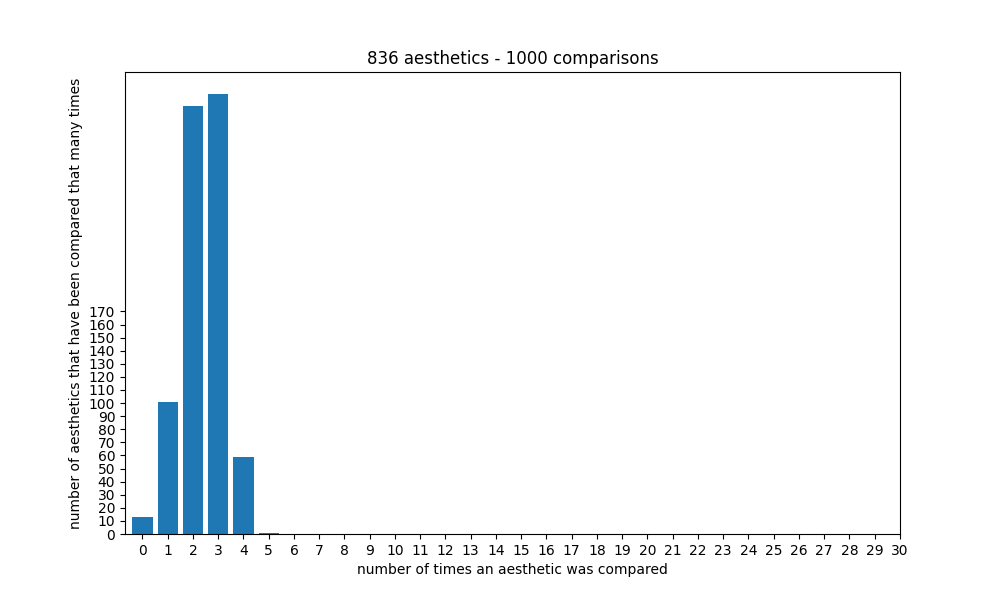
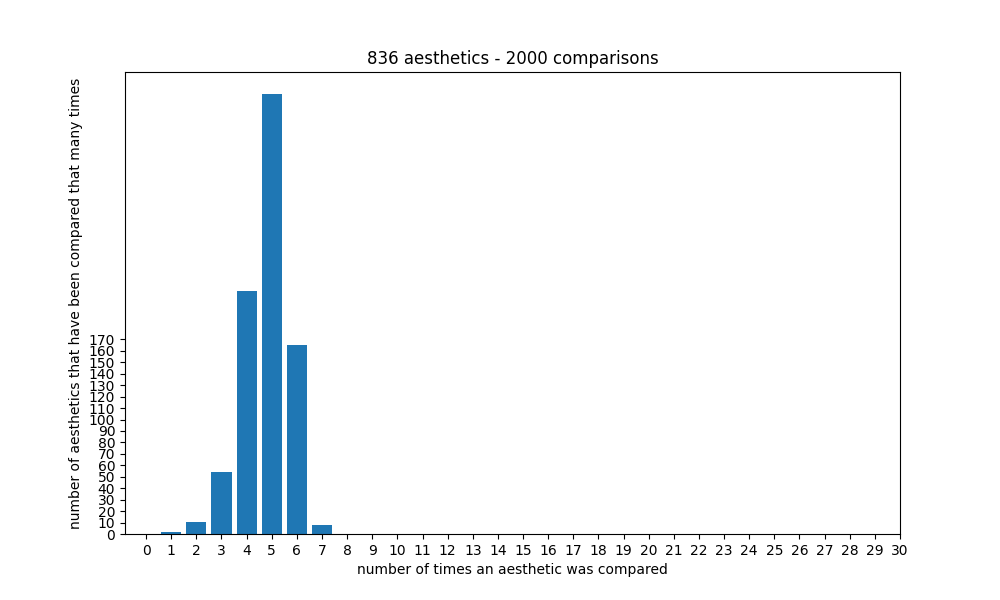
With the current number of aesthetics, it seems that the ranking starts getting good at around 2000 comparisons, and getting quite accurate/stable at around 3000 comparisons, because at that point each aesthetic will have been compared to another one around 7 times:
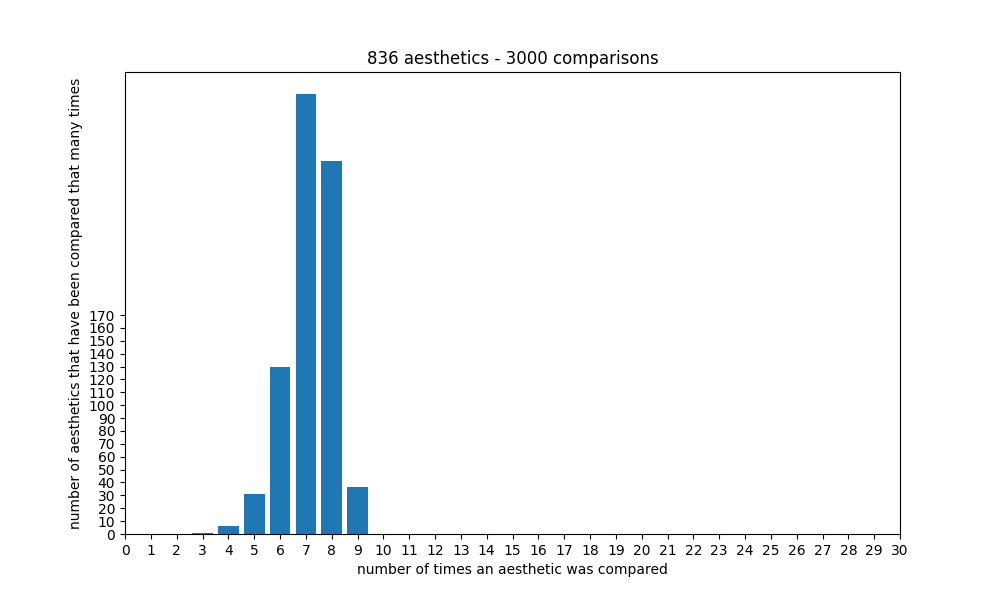
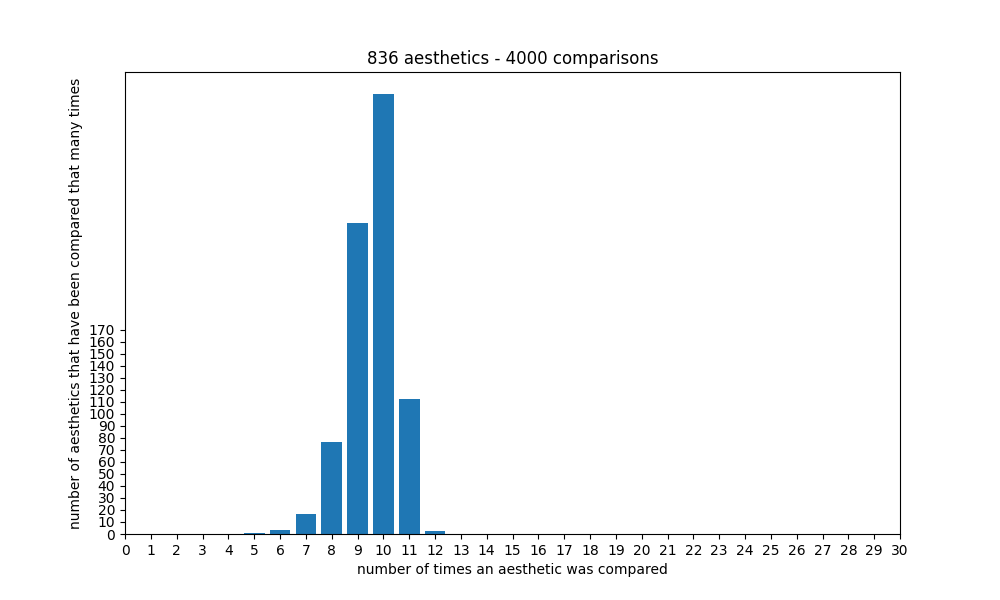
Is there something else I can do with my ranking?
Yeah! I've been getting interesting results from AI-generating images using a list of names of people's top aesthetics. If you join our
Discord server I can generate one for you!
How are comparisons chosen?
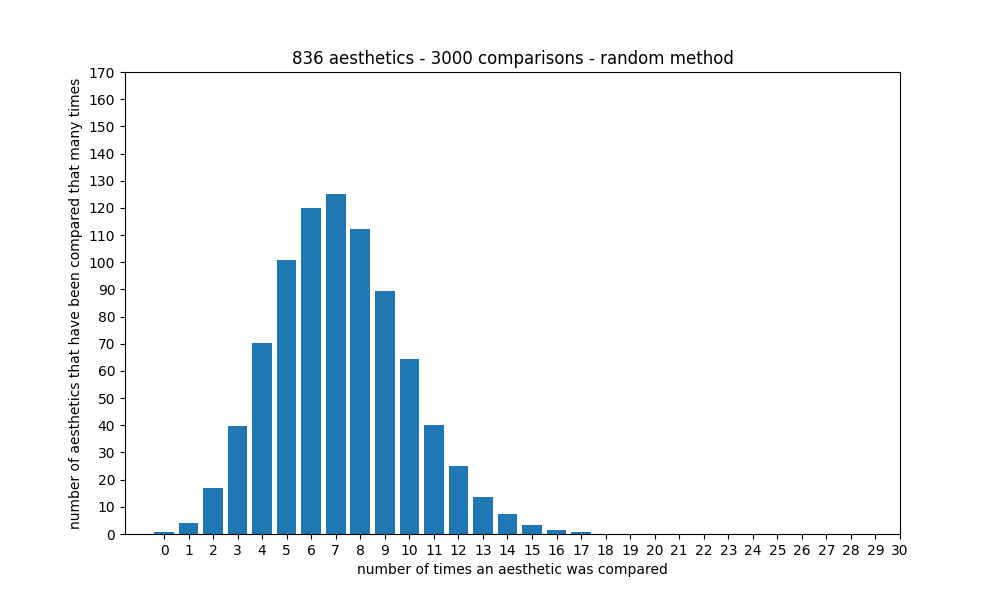
For each side, two aesthetics are selected at random, and the one that has been rated the least number of times will be chosen for that side. Unlike choosing each side completely randomly, this method statistically ensures that the distribution doesn't grow too wide - which would cause some aesthetics to be rated many times, and some only very few (or no) times, leading to inaccurate ratings or even missing aesthetics for the latter:
How does the similarity list work?
Due to how the statistics of the chosen metric work, assuming all rankings are considered or they are drawn completely randomly with a large enough sample size (which in practice, they aren't, since there seem to be universal likes and dislikes (the average of all user's ratings don't average out to the same value), but only more users will show what the real distribution looks like, the sample size is still too small to make any statistically sound conclusions), the average similarity tends toward 1/3 for a large number of ranked items, so {{ (distmean*100).toFixed(2) }}% (not 50% as perhaps expected, it is calculated as 1-1/Math.floor(Math.pow(n,2)/2)*1/3*(Math.pow(n,2)-1/n)), where n is the number of ranked items/aesthetics). So anyone with a similarity higher than this is more similar to you than average in the space of all possible rankings.
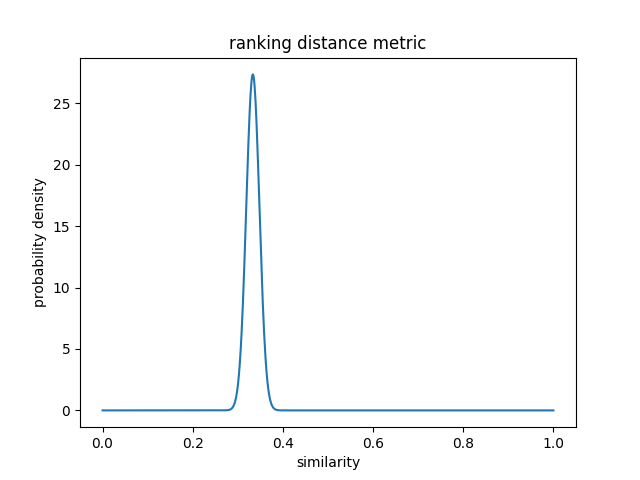
The standard deviation of this full distribution (a measure of how 'wide' it is) is also low, {{ (diststd*100).toFixed(2) }}%. So according to the
68–95–99.7 rule, 99.7% of all possible rankings lie within (±3*{{ (diststd*100).toFixed(2) }}%=) ±{{ (3*diststd*100).toFixed(2) }}% around the mean of {{ (distmean*100).toFixed(2) }}%. So it would be unlikely to see many other users with a similarity lower than ({{ (distmean*100).toFixed(2) }}%-{{ (3*diststd*100).toFixed(2) }}%=) {{ ((distmean-3*diststd)*100).toFixed(2) }}% or higher than ({{ (distmean*100).toFixed(2) }}%+{{ (3*diststd*100).toFixed(2) }}%=) {{ ((distmean+3*diststd)*100).toFixed(2) }}% unless there were thousands of users. Though again, in practice, this doesn't seem to be the case.
Furthermore, the distribution of all rankings would imply the following:
Assuming a world population of {{ worldpop.toLocaleString('en-US') }}, and the current number of aesthetics, {{ totalaesthetics }},
one can calculate the expected number of humans with at least a certain similarity value:
| sim. | #humans with at least this similarity |
|---|
| {{ ((0.2+(i-1)*0.01)*100).toFixed(2) }}% | {{ (worldpop * (1-ncdf((0.2+(i-1)*0.01), distmean, diststd))).toLocaleString('en-US', {minimumFractionDigits: 2, maximumFractionDigits: 2}) }} |
(
more info)
Again, this is not what I observe, as I see users over 42% similar to me, implying that preferences are indeed not randomly distributed, and there tend to be common preferences.
The maximum possible average rank difference (lowest possible similarity - 0%, achieved by having exactly the reverse ranking) is equal to the number of aesthetics {{ totalaesthetics }} divided by 2 (rounded down if the number is odd), so {{ Math.floor(totalaesthetics/2) }}. (
more info)
 Discord
Discord{kind=link}